
A Docker újoncai között gyakran nem egészen tiszta, hogy függ össze a futtatandó alkalmazás, akár webes szolgáltatás és a működését biztosító webszerver, illetve az ahhoz szükséges komponensek, mint például a PHP értelmező. Hol találkoznak egymással és milyen szoros kapcsolat van közöttük. Az a gondolkodásmód már nem működik, hogy összeállítasz egy vagy több webszervert és szépen egymás mellé sorakoztatod a weboldalakat virtuális hosztok segítségével. Persze, meg lehet oldani, de lemondanál a Docker legnagyobb előnyeiről. A kulcs az, hogy a szoftver szemszögéből közelíted meg a problémát. A kérdés pedig, hogy ebben az esetben miből mennyire van szükség és egyáltalán miért. Túl a különböző verziószámokon kényelmi és teljesítmény kérdések is befolyásolják a döntést. Nézzük, hogyan!
Tartalom
- Szükséges eltérő verziók
- Alkalmazás és webszerver kapcsolata
- Image-ek
- Szolgáltatások és konténerpéldányok
- Szervergépek száma
- Összefoglalás
Szükséges eltérő verziók
A legnyilvánvalóbb igény, ami már a virtuális gépeknél is jelen volt, hogy lehessen használni például többféle PHP verziót, különböző webszervereket vagy azonosakat eltérő verzióval, illetve tetszőleges adatbázist tetszőleges weboldalakhoz. Ezen szolgáltatások mindegyikének szüksége van egy portra és egy IP címre, amin figyelnek.
Megjegyzés: A PHP éppen megoldható lenne UNIX sockettel is, de a skálázhatóság szempontjából jobb TCP socketen indítani. Lehetne Apache HTTPD modulként is, de az előbb ismertetett okon túl azt sem szabad elfelejteni, hogy más szerver szolgáltatások is léteznek. Például NginX.
Ez azt jelenti, hogy úgy tudsz több verziót indítani egymás mellett, hogy különböző porton indítod őket vagy eltérő IP címen. A portok viszonylag könnyen megoldhatók, mivel a legtöbb esetben szabadon választhatók, de nem derül ki belőlük, hogy adott porton melyik szolgáltatás fut, ezért jobb lenne valami domén nevet hozzárendelni. Ehhez viszont az IP címből kell több. Lokális IP címekből elég sok van. Tehát például a 127.0.0.1, 127.0.0.2, stb... IP címek szabadon használhatók lennének, de ne feledd, hogy konténerekről van szó saját hálózattal, tehát a 127.0.0.1 IP cím általában azt jelenti, a szolgáltatás csak a konténeren belül érhető el.
Megjegyzés: Azért csak általában, mert hála a Docker, pontosabban a Linux képességeinek, van mód a konténerek között a hálózati interfészek megosztására. Ezen kívül a gazda operációs rendszer interfészeit is meg lehet osztani a konténerekkel, de a legtöbb esetben nem ez a cél, hanem a szeparáció.
Korábban azt mutattam be, hogyan lehet Debian 6-on több IPv4 címen is elérhetővé tenni a gépet. Ez az, amire már nincs szükség a Dockerrel, mert automatikusan hozzárendel IP címeket az induló konténerekhez az alapértelmezett hálózatán egy megadott tartományból. Új hálózatokat is létre lehet hozni akár automatikus, akár tetszőleges paraméterekkel. Így bár lehetőség van rá, nincs feltétlenül szükség bonyolult konfigurációra. Igaz, ezek nem nyilvános IP címek.
Van az úgy, hogy egy probléma megoldásával felmerül legalább egy másik. Nagyon könnyen lehet saját IP címmel akárhány konténert és így szervereket, szolgáltatásokat indítani, de azért néha a fejlesztői verziót is meg kell tudni mutatni másoknak, vagy távoli szerveren, esetleg virtuális gépen tesztelve a fejlesztés alatt levő program fájljainak szinkronizációja mellett a szolgáltatásokat nyilvános IP címen is elérhetővé kell tenni. Ezzel pedig visszaérkezve az eredeti problémához, hogy egy IP cím egy portján csak egy szolgáltatás futhat.
Ilyenkor lesz szükség egy proxy szolgáltatásra, ami az összes többi helyett figyel a nyilvános IP-n és továbbítja a belső hálózaton a megfelelő konténer felé a kéréseket. Elsőre ijesztően hangozhat, de megvannak erre már a bejáratott megoldások, így nem jelent majd nagy gondot. Talán most azt gondolod, nem fogsz távoli szerveren dolgozni, sem virtuális gépen, de elég, ha Windowson szeretnél Linux konténert indítani és nem lesz más választásod.
Ahogy tehát korábban utaltam rá, nem a különböző verziók futtatása fogja okozni a nehézséget, mert ez a feladat gyakorlatilag triviális a Dockerrel. Sokkal érdekesebb a külvilággal való megosztás, de mint látható, ez is megoldható.
Alkalmazás és webszerver kapcsolata
Az a cél tehát, hogy több verziót lehessen futtatni bármiből, tekinthető megoldottnak. De hogyan fog ebben a környezetben egy saját alkalmazás működni? Hogyan lehet egy új fejlesztésnek is konténeres szervert adni? Arról nem is szólva, hogy amikor PHP alapú weblapoknál minimum két konténer van (webszerver és PHP értelmező), hova kerül az alkalmazás? Valamelyik konténerbe vagy a két szék... akarom mondani konténer között a "földre"? A kérdés egyszerű, a válasz is első elgondolásra. Másodikra már kicsit nehezebb.
Annyi biztos, hogy a PHP értelmezőnek minden PHP fájlt látnia kell, és minden egyéb fájlt, amit PHP programból szeretnél kezelni. Ez lehet egy feltöltött fájl, egy kilistázandó mappa vagy akár egy JSON és XML konfiguráció is. Ez azt jelenti, hogy minden ilyen fájlt elérhetővé kell tenni a PHP konténerben. Ha nem vagy biztos benne, hogy pontosan mikhez kell hozzáférést biztosítani, akkor a legbiztosabb, ha mindent odaadsz a PHP-nek.
A Webszerver minden olyan fájlt kell lásson, amiket böngészőből elérhetővé kell tenni. Ez jelenti a weblap bizonyos PHP fájljait, amik a böngészőből fogadják a kéréseket, valamint a statikus fájlokat, mint a HTML, a képek, stílusfájlok vagy akár a JavaScript-ek. Elterjedt megoldás azonban, hogy a webszerver dokumentum gyökere az alkalmazás egyik almappájára van beállítva. Ebben a mappában van minden olyan fájl, amit a böngészőből el kell tudni érni. Ez lehet egyetlen darab index.php mellette a képekkel, szkriptekkel és CSS-sekkel. Ilyen esetben a webszervernek csak a dokumentum gyökérre van szüksége, és az azon kívül elhelyezett PHP és egyéb, nem a közönségnek szánt fájlokat nem kell tudnia elérni.
Megjegyzés: Bár a fenti állítás igaz, ha a dokumentum gyökér felett vannak szükséges htaccess fájlok, esetleg autentikációhoz generált htpasswd fájlok, azokat is meg kell osztani a webszerverrel. Ilyenkor vagy az egész projektet átadod mindkét konténernek, vagy a PHP konténerben elhelyezel egy automatizmust, hogy induláskor egy közös tárterületre másolja ezeket a fontos fájlokat. Erről majd későbbi fejezetekben lesz szó.
Vannak olyan állományok is, amik igazából futásidőben sehol sem kellenek már. Ezek lehetnek a projektben levő parancssori segédszkriptek, feldolgozandó fájlok, mint az SCSS, ami helyett már csak az elkészült CSS fájlok kerülnek a végleges programba, de például a dokumentációt is felesleges lehet a konténereknek átadni. Főleg a webszerver elől kell védeni, amit nem szándékozol publikálni, hiszen kis ügyességgel kritikus információkhoz lehetne jutni azok letöltésével. Ezen kívül, bár az ördög nem alszik, a mi tudatunk nem mindig áll a helyzet magaslatán. Egy programhibát kihasználva pedig akár a PHP konténerből is meg lehet szerezni bármit, így okos döntés lehet ezeket teljesen kihagyni a konténerekből.
A fájlok elérhetővé tétele a konténerekből több módon történhet.
- Fel lehet csatolni a gazda operációs rendszerről, de ekkor problémák lehetnek a fájlok jogosultságaival.
- Lehet készíteni saját image-et és belemásolni a fájlokat. Így az abból induló konténer is tartalmazza majd.
- Egy konténerben már elérhető könyvtárat osztott könyvtárnak lehet jelölni, így annak tartalma egy semleges területre lesz másolva automatikusan a gazda operációs rendszeren, ahonnét más konténereknek is át lehet adni. Ez a "Volume", magyarul "kötet".
Tehát azok a fájlok, amik sehol nem kellenek, nem lesznek sehova felcsatolva és nem lesznek image-be másolva. Fejlesztés közben a gyakran változó fájlokat, mappákat minimum fel kell csatolni a konténerekbe. Attól függően persze, melyiknek van szüksége rá. A többi fájlt már akár az image-be is be lehet másolni előre, de az sem baj, ha az egyszerűség kedvéért minden fel van csatolva a konténerbe ezzel felülírva az esetleg már ott levő fájlokat.
Megjegyzés: Említettem, hogy a felcsatolt mappák hátránya, hogy gondok lehetnek a jogosultsággal. Ennek ellenére mégis ezt javasoltam fejlesztés közben. Ennek az az oka, hogy minden változás után új image-et készíteni időbe telhet. Márpedig nyilván szeretnél gyorsabban dolgozni. A jogok problémájára ilyenkor megoldás lehet egy szkript készítése, ami helyreállítja azokat. Ha ez ráadásul minden induláskor lefut, akkor garantált, hogy a program minden fejlesztés megkezdésekor megfelelő jogosultságokkal fog indulni.
Amikor viszont a program elkészül és élesíteni kell, már ajánlott egy saját image-et készíteni a hivatalos PHP image-et örökölve, majd ebbe bemásolva a program forráskódját. Meg lehet jelölni a webszerverrel megosztani kívánt mappákat, majd a PHP konténer elindulása után a webszerver konténer indításakor el lehet kérni a PHP konténer összes megosztott mappáját. Másik lehetőség, hogy a PHP konténer indulásakor az abban levő megosztott mappák egy azonosítót, nevet is kapnak, amivel hivatkozni lehet a gazda operációs rendszeren elfoglalt helyére, így a webszervernél már név szerint lehet egy vagy több mappát felcsatolni a PHP konténerből.
Megjegyzés: Annak oka, hogy a PHP image-be javaslom másolni elsődlegesen a projektet, azon túl, hogy ott van a legtöbb fájlra szükség, az, hogy webszerverből többféle lehet, de a megfelelő PHP verzió nem helyettesíthető. Igaz, ha vannak htaccess fájlok, amik kimondottan Apache HTTPD-vel működnek, korlátozzák a lehetőségeket, de még mindig könnyebb elkészíteni a htaccess alternatíváját a választott webszerverhez, mintha a PHP értelmező lenne a probléma.
Felmerülhet a kérdés, hogy miért ne állíthatnál be egy PHP konténert, amihez minden weboldalt csatlakoztatsz. Ekkor fel kellene csatolni az összes PHP projektet a PHP konténerbe, a webszervert az összes projekt fényében kellene konfigurálni, az egyedi beállításokat elfelejthetnéd, a hordozhatóságot úgyszintén, és a frissítéseket sem tudnád külön‑külön elvégezni. Minden PHP projekt látná a másikat, hacsak nem trükközöl a jogosultságokkal, ráadásul az erőforrásokat sem szabhatnád projektre. Gyakorlatilag értelmetlen lenne a konténer azt az egy előnyt leszámítva, hogy könnyen lehet törölni az így telepített szervereket.
A fentiekből következik, hogy a webszerver és a PHP konténer mindig egy konkrét alkalmazáshoz kötődik. Ennek előnye, hogy bármelyik weblapot bármikor leállíthatod, frissítheted anélkül, hogy a többi programot ez befolyásolná. Lesz viszont jó eséllyel adatbázis is. Ha ez egy olyan relációs adatbázis, mint például a MySQL, akkor igen nagy erőforrás pazarlás lenne éles környezetben minden alkalmazáshoz saját MySQL szerver. Az ugyanis nagyon hamar sok memóriát lefoglalhat. Alapbeállítások mellett a fél giga szinte garantált. A nagyobb programok persze kaphatnak saját MySQL szervert igény esetén, de sokszor elég, ha egy adatbázis szerverhez több alkalmazás is csatlakozhat. Mivel fejlesztés közben ritkán megy párhuzamosan több projekt is, ebben az időszakban érdemes mégis ezt is projektenként beállítani külön konténerben.
Image-ek
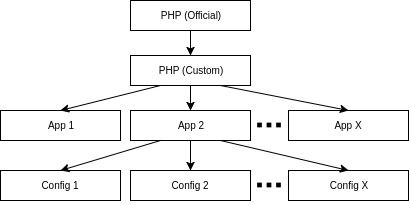
Az előző pontból kiderült, hogy a projekt fájljait akár saját image nélkül is fel lehet csatolni a konténerekbe. Ettől még a konténerhez szükség van egy image-re. Ez viszont lehet hivatalos image is a Docker Hub-ról, vagy más által elkészített. Ha nincsenek a projektben olyan igények, amik indokolnák a saját, módosított image-et, akkor akár az összes azonos verziójú PHP-hez használható ugyanaz az image. Ugyanez igaz a webszerverre is. Az egyedi igények mégis gyakoriak, ezért szinte biztos lesz legalább egy saját PHP image-ed, és élesben pedig minden alkalmazáshoz az egyedi vagy hivatalos image-ből örökölt image, a programot tartalmazva. Ráadásul még ezt is tovább lehet finomítani, mert lehet olyan program, amit többször, különböző módon kell elindítani. Ilyen, ha a szoftver valójában egy keretrendszer vagy tartalomkezelő. Ilyenkor a különbség a konfigurációban rejlik és amennyiben van értelme, és nem adható meg paraméterezéssel a konténer indításakor, ezt is létre lehet hozni új image-ként. Ezek ugyanakkor jelszavakat és hasonlóan titkos adatokat ne tartalmazzanak lehetőség szerint!
Megjegyzés: Felcsatolni is lehet konfigurációs fájlokat, ami remekül működik fejlesztés közben, de a programok hordozása sokkal egyszerűbb, ha minden egy image-ben van benne, ami bármikor, bárhol letölthető egyszerűen és akárhol, akárhány gépen, akárhány példányban elindíthatók belőle konténerek. Az image-be nem rakható adatok pedig átadhatók paraméterben a konténernek, vagy speciális módon felcsatolhatók bizonyos rendszereken egy klaszterben is, a gépek között automatikusan hordozható módon, előre definiált konfigurációkból.
Szolgáltatások és konténerpéldányok
Tettem arra is már utalásokat, hogy egy alkalmazásból el lehet indítani egyszerre több példányt is, amik között megoszlik a terhelés. De mikor van ennek értelme?
Egy PHP értelmezőben vagy egy Apache HTTPD szerveren is konfigurálható a kéréseket kezelő processzek viselkedése. Limitálni lehet a maximális vagy minimális processzek számát, a memóriát, és hogy mikor szűnhet meg egy folyamat. De amikor a terhelés megugrik, ezeket manuálisan kellene megváltoztatni, mert az egy konténer már nem képes kiszolgálni a kéréseket. Ha viszont el tudsz indítani egy második, az előzővel azonos konténert, majd valamilyen algoritmus alapján néha az egyik, néha a másik kapja a kéréseket, az elérhető erőforrásokat máris megdupláztad.
A másik eset, amikor több gép is be van kötve egy klaszterbe, és ezek bármelyikén elindulhatnak a konténerek. Ha mindenből csak egy példány fut valamelyik gépen, de az a gép kiesik, még akkor is időbe telik a programnak helyreállnia, ha automatikusan észleli a klaszter a hibát és elindítja egy új gépen.
Ennek fejlesztés közben maximum akkor van jelentősége, ha a több példányban futtatást szeretnéd konkrétan letesztelni. A terheléssel ott valószínűleg nem lesz olyan probléma, amit újabb konténerrel kellene orvosolni.
Szervergépek száma
A gépek száma fejlesztési időben ritkán lesz egynél több. Akkor is inkább szintén csak tesztelési célból. Élesben viszont, ha fontos, hogy minél kevesebb kiesés legyen a szolgáltatásokban, érdemes lehet több gépre is szétszórni egy-egy példányt. Az adatokat ekkor már nem lehet közvetlenül a konténert futtató gép fájlrendszeréről betölteni. Szükség lesz valamilyen hálózati fájlrendszerre. Cserébe viszont a gépek bármikor leállíthatók, vagy felvehető új is a klaszterbe.
Összefoglalás
A futtatandó konténerek száma tehát több tényezőtől függ. Beleértve a alkalmazás bonyolultságát, a várható terhelés mértékét, a magas rendelkezésre állás igényét és a hadba állított gépek számát is, amennyiben vannak globális szolgáltatások, amikből minden gépen kell egy példány. Saját gépen fejlesztés közben ezek nem nagyon fognak elszaporodni, de érdemes követni azt az elvet, hogy egy konténerben egy program fut, így növelve a rugalmasságot és persze esetenként bonyolítva a kommunikációt.
Fejlesztés közben meg lehet spórolni a saját image-eket, de érdemes elkezdeni gondolkozni egy alkalmas hierarchiáján az image-eknek. Amit csak lehet, másolj image-be, de az érzékeny adatokat, jelszavakat hagyd ki és a konténer indulásakor paraméterben add át vagy Configban, Secretben.
Saját gépen nem muszáj klasztert beállítani virtuális gépekkel, de gondolj rá, hogy a programot úgy készítsd, hogy működőképes legyen klaszteres környezetben is, amennyiben nem egy saját szervergépre szánod, aminek ismered a paramétereit.
Ha kérdésed van a leírtakkal kapcsolatban, kérdezz bátran akár Facebookon, vagy itt, kommentben.